

企业档案
会员类型:会员

已获得易推广信誉 等级评定
171成长值
(0 -40)基础信誉积累,可浏览访问
(41-90)良好信誉积累,可接洽商谈
(91+ )优质信誉积累,可持续信赖
易推广会员:8年
工商认证 【已认证】

最后认证时间:
注册号: 【已认证】
法人代表: 【已认证】
企业类型:生产商 【已认证】
注册资金:人民币万 【已认证】
产品数:91228
参观次数:11305518
技术文章
蛋白质与高通量药物筛选化合物库 | MedChemExpress
点击次数:506 发布时间:2021/10/8 17:24:03
天下苦“蛋白质三维结构”久矣
天然蛋白质具有特定的三维空间立体结构。一生二,二生三,三生空间结构,构成蛋白质肽链的氨基酸线性序列 (一级结构) 包含了形成复杂三维结构所需要的全部信息。理论来说,已知蛋白质氨基酸序列组成,就能轻松获得蛋白质三维结构,但现实远没有那么简单。目前已知氨基酸序列的蛋白质分子约有 2.1 亿个,但截至目前 RCSB PDB (www.rcsb.org) 上收录的被实验解析的蛋白质三维结构仅有 18,1295 个,不到蛋白质总数的 0.1%。究其根本,通过 X 射线衍射、核磁共振或冷冻电镜等方法获得蛋白质三维结构,哪个不耗时费力、需要大量资金投入?另,计算机预测蛋白质结构有诸多限制,SWISS-MODEL 要求序列同源性 > 30%,I-TASSER 要求序列能穿到现有结构,ROBETTA 要求氨基酸序列 < 200。天下苦“蛋白质三维结构”久矣!直到 AlphaFold2 横空出世。
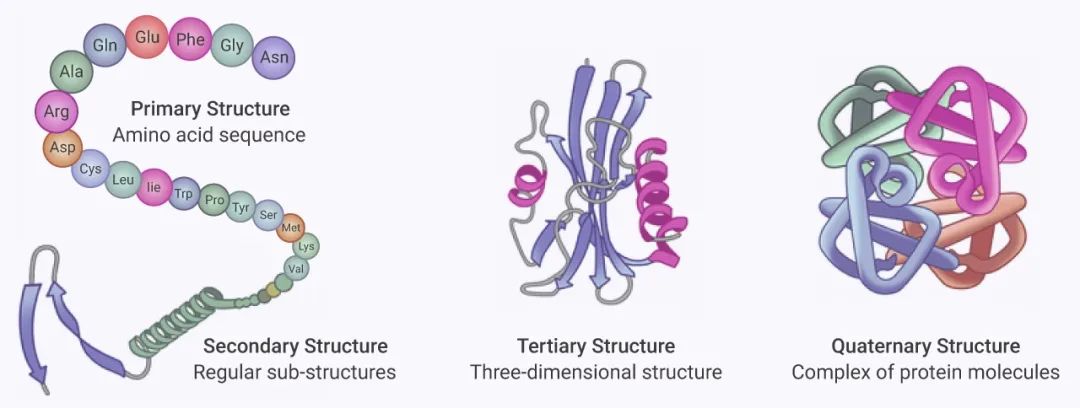
图 1. 蛋白的一、二、三、四级结构
AlphaFold2 横空出世
2020 年末,AlphaFold2 (DeepMind 公司开发的 AI 程序) 在 CASP14 (第 14 届蛋白质结构预测比赛) 中将蛋白结构预测准确性从 40 分拔高到 92.4 分,实现了原子精度或者接近原子精度的结构预测,震惊生物界。2021 年 7 月 16 日,DeepMind 团队在 Nature 上公布了 AlphaFold2 的源代码。仅一周后,DeepMind 团队再发 Nature,公布 AlphaFold 数据集,再次引爆科研圈!AlphaFold 数据集覆盖几乎整个人类蛋白质组 (98.5% 的所有人类蛋白),还包括大肠杆菌、果蝇、小鼠等 20 个科研常用生物的蛋白质组数据,蛋白质结构总数超过 35 万个!而且,数据集中 58% 的预测结构达到可信水平,其中更有 35.7% 达到高信度!

图 2. Alphafold 数据集网站
(免费开放网址:alphafold.ebi.ac.uk)
(免费开放网址:alphafold.ebi.ac.uk)
深究 AlphaFold2 计算模型发现,AlphaFold2 没有借鉴 AlphaFold 使用的神经网络类似 ResNet 的残差卷积网络,而是采用*近 AI 研究中兴起的 Transformer 架构,其中与文本类似的数据结构为氨基酸序列,通过多序列比对,把蛋白质的结构和生物信息整合到了深度学习算法中。从模型图中可知,AlphaFold2 与 AlphaFold 不同,并没有采用往常简化了的原子间距或者接触图,而是直接训练蛋白质结构的原子坐标,并使用机器学习方法,对几乎所有的蛋白质都预测出了正确的拓扑学的结构。统计 AlphaFold2 预测的结构发现:大约 2/3 的蛋白质预测精度达到了结构生物学实验的测量精度。
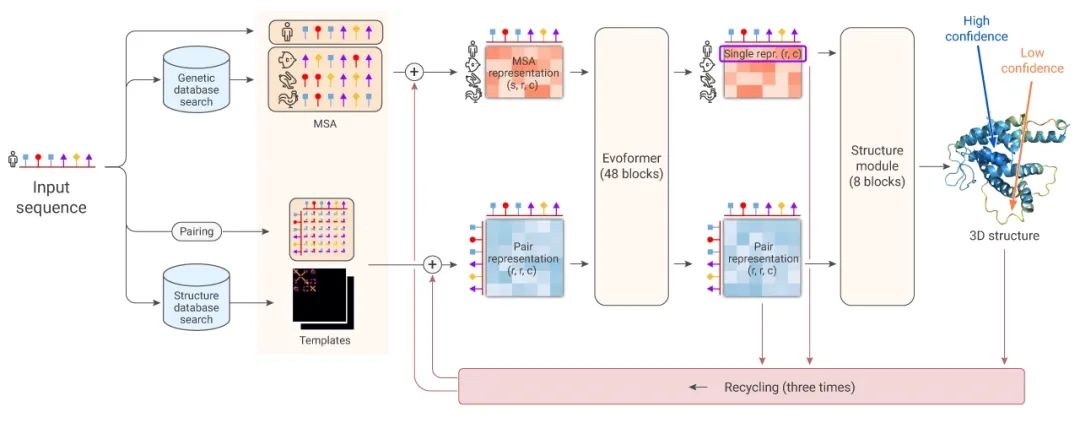
图 3. AlphaFold2 计算蛋白三维结构模型图
ZINC20 新增数十亿分子
AlphaFold2 给药物研发带来的革命性变化不言而喻:AlphaFold2 能低成本预测疾病相关的蛋白质结构,进而通过药物重定位、虚拟筛选等方法寻找这些疾病的潜在药物。而化合物数据库作为虚拟筛选的重要工具,同样决定了小分子药物研发的速度和质量。ZINC 是一个汇总了化合物相关信息的公开数据库,是支持 2D、3D 化合物分子形式下载以及可进行快速分子查找、类似物搜索的服务网站,其分子量已经目前增长到近 20 亿,其中可购买的 13 亿化合物来自于 150 个公司共 310 个产品目录。尽管全球库存化合物的数量 (现在约为 1400 万) 每年仅增长百分之几,但按需定制化合物数量几乎呈指数增长,目前按需定制化合物的需求量已经增长至数百亿个分子,数年后将达到千亿级。ZINC20 (zinc20.docking.org) 新增百亿个按需定制化合物 (暂未添加到 ZINC 库中),这些化合物在骨架和分子多样性上都明显优于物理筛选数据库。
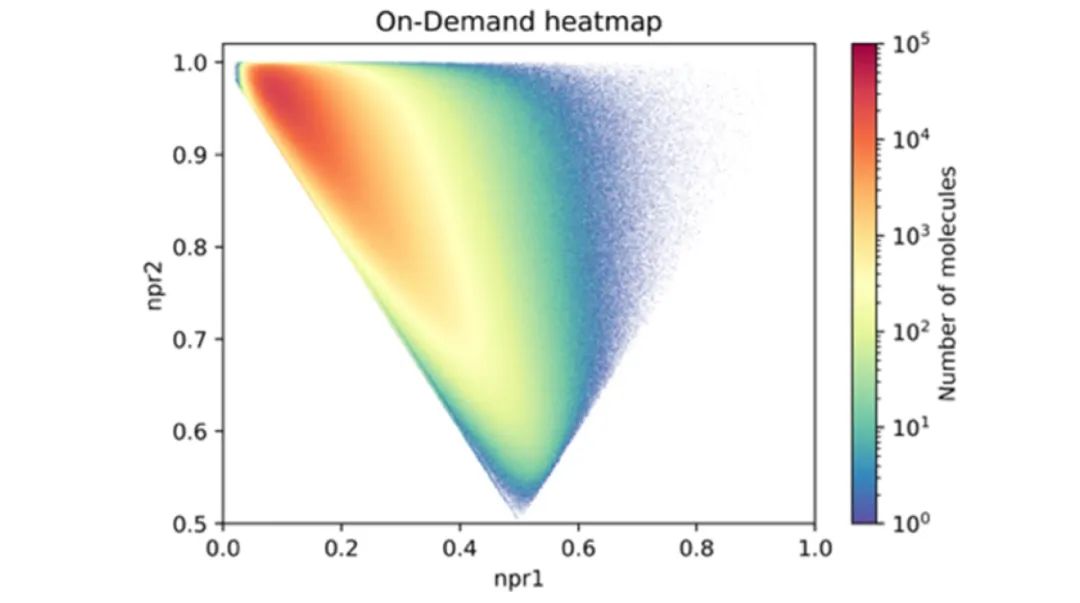
图 4. 按需定制化合物增长需求量 (NPMI 分析)
VirtualFlow, 5 小时虚拟筛选 10 亿分子
MCE 拥有专业的虚拟筛选团队、高性能的计算机服务器、高度标准的数据隐私管理,可提供专业的分子对接、虚拟筛选服务。更有 40 余种高通量化合物库,涵盖 600 万有现货、可重复供应、结构多样、具有类药性的化合物,任您挑选。*终项目报告包含背景调研、流程概述、结果分析,更有符合文章发表要求的 2D/3D 分子对接图。
MCE 一站式药物筛选平台,虚拟筛选、化合物活性筛选、基于离子通道的化合物筛选,“快,不止一步”!2021.10.31 前下单,享受折后双倍积分 (MCE 开学季活动),快来 Pick。
| 相关产品 |
| MCE Bioactive Compound Library MCE 活性化合物数据库,含有 11,000+ 已知高活性的化合物集合,结构多样,是老药新用、新适应症筛选的有效工具。国内现货供应。 |
| MCE Fragment Library 基于 RO3 原则精选 14,000+ 片段化合物,用于 FBDD。国内现货供应。 |
| HTS Compound Library 包含 2,115,979 种具有独特结构和性质的化合物,数量大,结构多样性丰富。 |
| Advanced Library 包含 493,968 种类先导化合物,化合物的多官能团和类先导化合物的特性使 Advanced 库成为先导化合物发现的有效工具。 |
| Premium Library 46,441 种分子特性 (高 Fsp3、低 logP 和 MW ) 的化合物集合,精选库。 |
| Discovery Diversity Set 10 Enamine Discovery Diversity Sets (DDS) 专注于新型化合物结构式,适合新型化合物的随机筛选。DDS 库含有共 60,800 个新型化合物。Discovery Diversity Set 10 由高度特异且不重复的 10,560 个化合物组成。 |
| Discovery Diversity Set 50 Enamine Discovery Diversity Sets (DDS) 专注于新型化合物结构式,适合新型化合物的随机筛选。Discovery Diversity Set 50 是 Discovery Diversity Set 10 的补充,由 50,240 个化合物组成。 |
| Chemspace Lead-Like Compound Library 来源于 Chemspace,包含 981,244 个类先导化合物,结构多样,适用于高通量筛选。 |
| Chemspace Scaffold derived set Chemspace 骨架库,精心选择 3,373 个骨架,每个骨架 3 个化合物,在骨架基础上添加官能团,增加化合物空间结构覆盖率。 |
| Chinese National Compound Library 国家化合物样品库有近 140 万个化合物,具有结构多样化、存储专业化、管理集中化、信息系统化和质控标准化等特点。 |
| Life Chemicals 50K Diversity Library Life Chemicals 50K Diversity Library 是一个相当大的高度多样化的化合物库,由 50,240 个类先导物化合物组成。 |
| Life Chemicals HTS Compound Collection 来源于 Life Chemicals,包含 494,471 个化合物,多样性丰富,适用于高通量筛选。 |
| Maybridge Screening Collection 来源于 Maybridge,包含 53,000 种高度多样的类先导化合物,是药物筛选的有效工具。 |
| Specs HTS Compounds Library 来源于 Specs,包含 210,070 种化合物,多样性丰富,适用于高通量筛选。 |
注:
1、每个库中的分子数量实时变动,以上分子数量仅供参考,以官网实时数据为准。
2、更多数据库详见 MCE 官网。
参考文献
1. Callaway E. DeepMind's AI for protein structure is coming to the masses[J]. Nature, 2021.
2. Jumper J, Evans R, Pritzel A, et al. Highly accurate protein structure prediction with AlphaFold[J]. Nature, 2021:1-11.
3. Baek M, Dimaio F, Anishchenko I, et al. Accurate prediction of protein structures and interactions using a three-track neural network[J]. Science.
4. JIrwin J J, Tang K G, Young J, et al. ZINC20-A Free Ultralarge-Scale Chemical Database for Ligand Discovery [J]. Journal of Chemical Information and Modeling, 2020, 60, 12, 6065–6073.
5. Gorgulla C, Boeszoermenyi A, Wang ZF, et al. An open-source drug discovery platform enables ultra-large virtual screens. Nature. 2020; 580(7805):663-668.
相关产品
-
 电议 型 号:
电议 型 号: -
电议 型 号:
-
电议 型 号:
-
电议 型 号:
-
电议 型 号:


