

企业档案
会员类型:会员

已获得易推广信誉 等级评定
(0 -40)基础信誉积累,可浏览访问
(41-90)良好信誉积累,可接洽商谈
(91+ )优质信誉积累,可持续信赖
易推广会员:5年
工商认证 【已认证】

最后认证时间:
注册号: 【已认证】
法人代表: 【已认证】
企业类型:生产商 【已认证】
注册资金:人民币万 【已认证】
产品数:86101
参观次数:3668613
技术文章
Chemdiv 化合物设计软件
点击次数:101 发布时间:2022/3/22 17:27:05
随着组合化学技术的发展,现代药物化学通过计算机虚拟合成的方法,可以得到规模非常庞大的筛选化合物库,理论上可以合成的类药化合物超过1040个。显然,切实地合成每一个药物是不太现实的事情,因此必须利用一些规则去进行筛选,以减少合成的规模。一般的操作流程是从大量已有的数据中总结出规律,再利用这些规律进行虚拟筛选。面对如此大量的数据,就需要一系列融合了化学、数学及计算机等学科的化合物库设计工具,用于“从数据到信息,从信息到知识”的整个化学信息处理过程。常见的软件有Chemosoft(Chemdiv), SmartMining (Chemdiv),ISIS Base(MDL),KNIME,NeuroSolution(NeuroDimension),PyMOL(Schrödinger),ICM Pro(Molsoft),AutoDock(Scripps),Discovery Studio(Accelrys),MOE(CCG)等等。
这些软件的用途十分广泛,大致可以分为以下几类:
1. 数据储存与管理。
每一个化合物的化学参数,光谱数据,纯度数据,生物活性测定值等各种相关数据被收集储存在数据库中,并实现快速调用与操作。这一步是后续所有分析处理的提条件。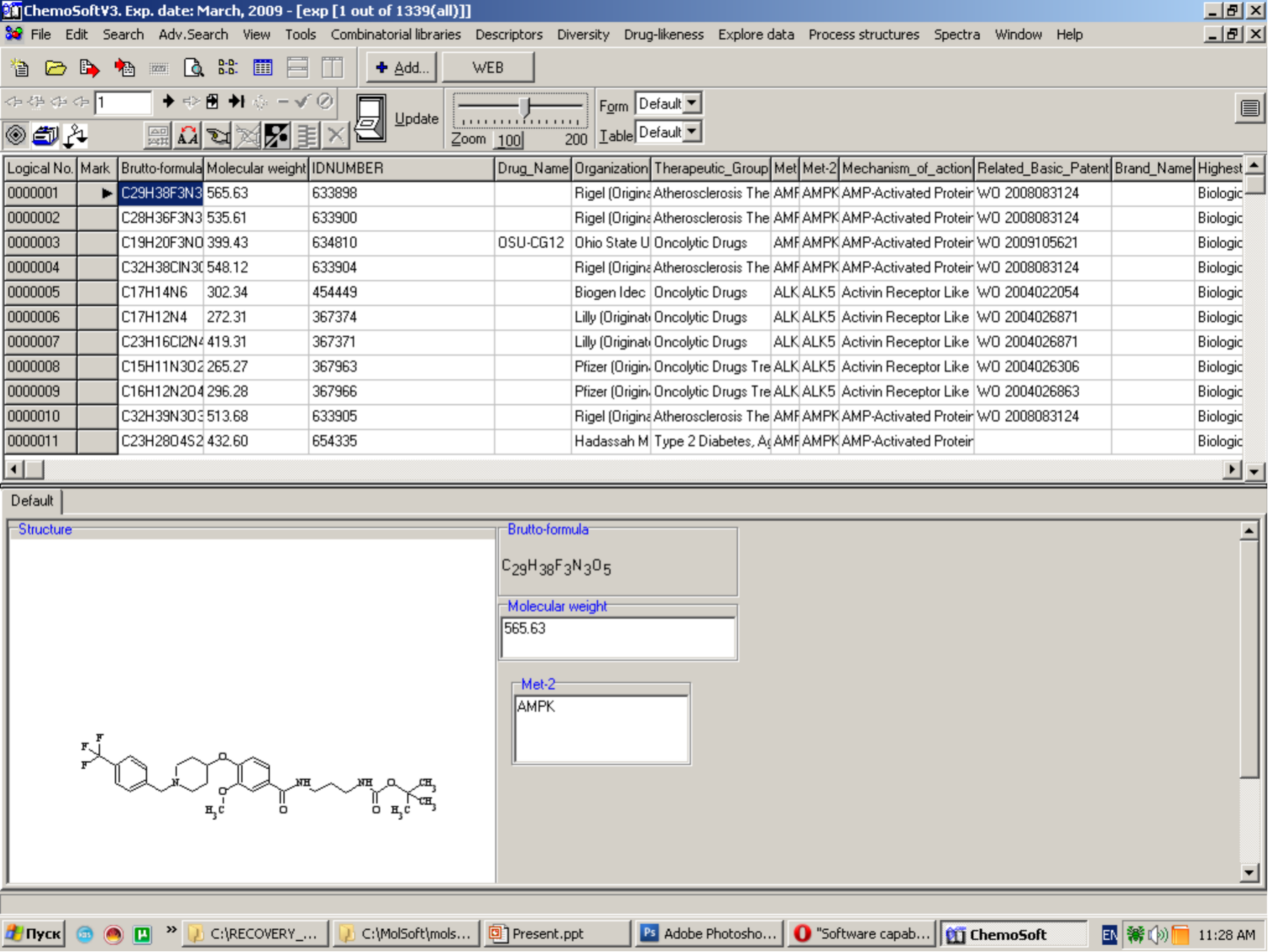
利用Chemosoft查看化合物信息
2.构效关系研究。
是指通过对现有活性化合物的分析,用数理统计的方法(如遗传算法、人工神经网络、支持向量机和投影寻踪回归等)建立起构效关系模型,来衡量化合物结构与生物活性之间的关系。二维定量构效关系法主要是以化合物整体结构为参数建立构效关系模型。典型的方法有Hansch方法、free-wilson方法、分子连接性方法等。而三维定量构效关系法则是引入化合物的三维结构信息研究构效关系。这种方法间接反映了小分子与大分子相互作用过程中非键相互作用特征。常用的方法是比较分子场法(CoMFA)、比较分子相似性方法(CoMSIA)。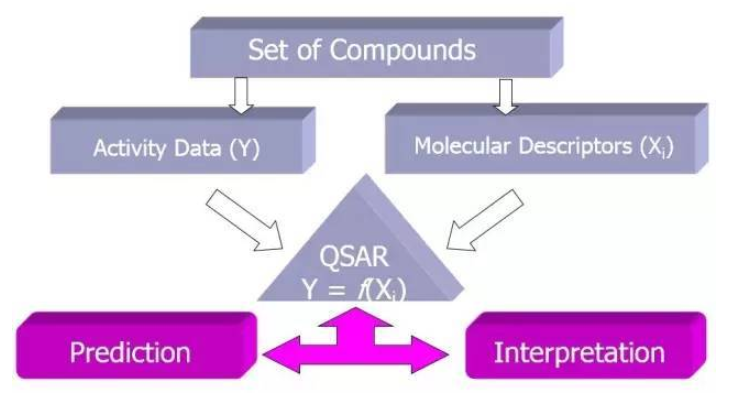
构效关系研究基本思路
3.虚拟数据库设计。
常用的方法是基于配体结构的设计:在生物靶点结构未知或以配体设计为侧重点的情况下,通过研究与靶点有特异性结合的配体结构性信息,进行药物设计的方法。可以利用已知活性分子的特定结构片段作为“特权”结构,寻找2D子结构;或是通过3D药效团分析,选择具有相似药效团的分子。另一种则是基于靶点结构的设计方法:以靶点结构为筛选模板,从与目标结合位点互补的可合成模板开始设计药物分子,然后再考虑用于每个随机点的可用分子砌块数据库。选择取代基是基于它们与活性区域的特定残基相互作用能力以及合成的可行性。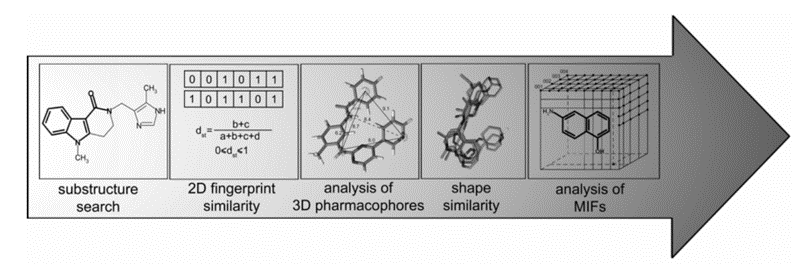
基于配体结构的设计方法
4.数据挖掘。
通过分析已有的化合物数据,产出对亚结构、二维/三维相似性、分子形状、骨架、药效团层面的信息度量,从而开展其他化合物的选择。聚类分析就是一种重要的挖掘方法,通过寻找数据间的相似性来对数据进行分类,不仅可以优化大规模数据库的查询,还可以发现数据中隐含的有用信息。
三维聚类分析示例
5.统计分析。
主成分分析、因子 分析等方法被用来进行化合物描述因子的降维,从而可以更加简单有效地表述分子信息并降低计算的复杂程度。例如主成分分析是应用广泛的多维数据分析技术。它通过正交变换将一系列可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫主成分。通过这种方式可以把多个变量转换成二维/三维变量,在不减少变量的条件下,对数据进行降维处理。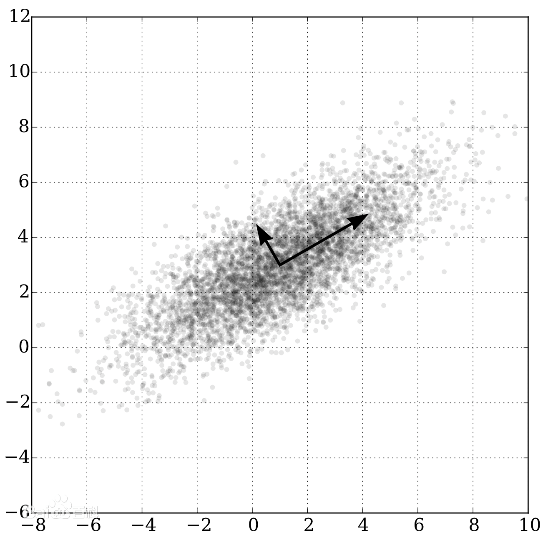
主成分分析示例
6.可视化分析。
通过图表的方式自动地进行数据的过滤和表达,再根据生成的结果可以进行分析。例如Kohonen提出的SOM(自组织映射)是将矢量样本集映射到二维晶格上,从而保留原始空间的拓扑结构,用于高通量筛选数据的分析和可视化。不仅可以用作结构-活性关系的指标,而且可以作为分类系统的基础,允许对组合库进行预测建模。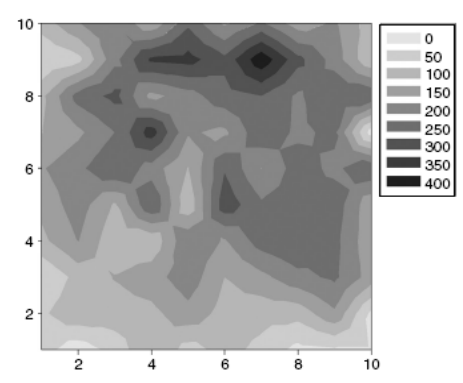
基于SOM的可视化分析示例
设计软件示例
- KNIME
- NeuroSolutions
- PyMOL
- Autodock
- Discovery Studio
设计实例分析
酪氨酸激酶是很有吸引力的癌症治疗生物学靶点,它们的异常信号常常与肿瘤的发展有很大的关系。此外,它们在其他疾病中也发挥着关键作用,例如炎症和类风湿关节炎。下图是酪氨酸激酶靶点库设计的具体步骤。
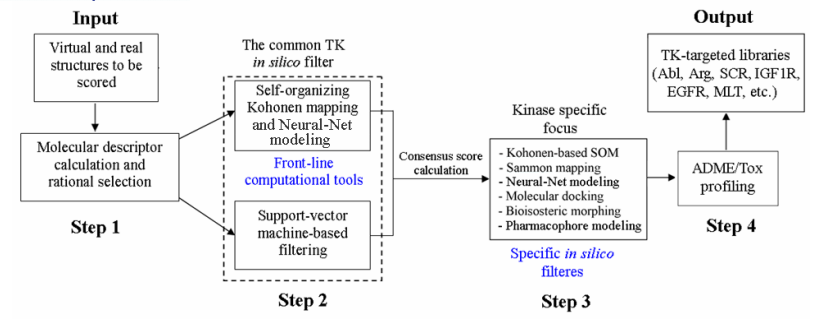
在这些步骤里,Chemdiv采用各种设计软件进行综合分析与筛选:
1. 利用Chemosoft,MOE等软件进行虚拟合成设计和过滤,采用独特的生物等排变构等方法设计具有高知识产权价值的酪氨酸激酶配体。
2. 利用SmartMining构建用于靶点库分析的神经网络模型,尤其是自组织Kohonen映射。Sammon映射和支持向量机等算法也被应用来进行酪氨酸激酶靶点库设计。
3. 利用Autodock等软件进行分子对接。
4. 利用Discovery Studio等软件进行ADME / Tox评估,包括预测P450-介导的代谢和毒性以及相关药代动力学参数。
总结
除了上述介绍的内容外,不断的有新的设计原理和软件正被开发出来。这些工具的使用可以使筛选化合物的设计更加合理有效,节省筛选成本,加快药物研发的进程。
作为全球知名的类药化合物品牌,Chemdiv具有先 进的软硬件设备,以及经验丰富的药化学家和生物学家,在化合物库的设计上具有明显优势,可以结合多种软件特点设计符合用户需求的类药化合物库。
陶术生物是Chemdiv中国的独代供应商,可以提供超过150种Chemdiv设计的化合物库,还能根据客户需求量身定制化合物库。
原创作者:上海陶术生物科技有限公司
相关产品
-

-
电议 型 号:T6561
-
-
-
电议 型 号:T6558


